Chapitre 1
AutomA Playbooks
Introduction
Ce chapitre traite de la documentation sur la partie des playbooks et des questions pour l’ensemble des recommendations mise à disposition des utilisateurs. Vous trouverez le projet AutomA-Playbooks sur github ainsi que la démarche à suivre pour contribuer sur le projet dans la partie Contribuer.
Arborescence
L’arborescence du dépôt github se découpe selon la forme suivante :
└── KERNEL
└── OS
└── VERSION
├── CATEGORY
│ ├── REFERENCE
│ │ └── LEVEL
│ │ └── RXX_ACTION_NAME
│ │ ├── playbook.yml.j2
│ │ └── questions.yml
│ └── REFERENCE2
│ └── LEVEL2
│ └── CXX_ACTION_NAME2
│ ├── playbook.yml.j2
│ └── questions.yml
├── CATEGORY2
│ └── REFERENCE
│ └── LEVEL
│ └── RXX_ACTION_NAME3
│ ├── playbook.yml.j2
│ └── questions.yml
└── CATEGORY3
└── REFERENCE2
└── LEVEL
└── RXX_ACTION_NAME4
├── playbook.yml.j2
└── questions.yml
A la date du 30 novembre 2023, le projet ressemblait à l’arborescence suivante :
└── LINUX
└── DEBIAN
└── 12
├── KERNEL
│ └── ANSSI
│ └── 1_INTERMEDIATE
│ └── R11_CONFIGURE_YAMA_LSM
│ ├── playbook.yml.j2
│ └── questions.yml
├── NETWORK_STACK
│ └── ANSSI
│ └── 1_INTERMEDIATE
│ └── R13_DISABLE_IPV6
│ ├── playbook.yml.j2
│ └── questions.yml
├── PACKAGE_MANAGEMENT
│ └── ANSSI
│ └── 0_MINIMAL
│ └── R61_PERFORM_REGULAR_UPDATES
│ ├── playbook.yml.j2
│ └── questions.yml
├── PERMISSIONS
│ └── ANSSI
│ ├── 0_MINIMAL
│ │ └── R54_ACTIVATE_STICKY_BIT
│ │ ├── playbook.yml.j2
│ │ └── questions.yml
│ └── 3_REINFORCED
│ └── R36_CHANGE_UMASK_VALUE
│ ├── playbook.yml.j2
│ └── questions.yml
└── USERS
└── ANSSI
└── 0_MINIMAL
└── R30_DISABLE_UNUSED_USER_ACCOUNTS
├── playbook.yml.j2
└── questions.yml
Nous avons réfléchis et choisi cette structure de dossier pour permettre une meilleure intégration des futures règles et environnements de durcissement. Le principe de cette structure légèrement conséquente est de permettre une meilleure modularité du projet.
Vous voulez contribuer au projet en ajoutant des règles de durcissement pour windows serveur 2022 ?
Vous devez créer l’arborescence (si inexistance), ici /WINDOWS/SERVER/2022/. Ensuite, vous devez créer la structure suivante selon les actions de durcissement que vous voulez ajouter. De manière générique, voici les dossiers à créer (dans l’ordre) :
- CATEGORY : Le nom de la catégorie dans laquelle la règle de durcissement s’inscrit. Il est possible que des actions de durcissements puissent être dans plusieurs catégories. Dans ce cas, choississez la catégorie dans laquelle cela serait le plus logique mais en cas de questionnement, vous pouvez ouvrir une issue sur le projet Github ou par mail à automa.project@proton.me.
- REFERENCE : Le référentiel dans lequel l’action de durcissement est tirée. Nous basons la globalité de nos actions sur les recommandations de l’ANSSI mais il est possible d’utiliser d’autres référentiels tel que le CIS.
- LEVEL : Ce dossier est tiré du système de niveau de l’ANSSI dans son guide de Recommandations de sécurité relatives à un système GNU/Linux. Dans ce guide, ils proposent une grille de niveaux de durcissement qui permet donc de situer le niveau de l’action de durcissement. Il est nécessaire de bien choisir le niveau de durcissement des règles de durcissements pour permettre une meilleure segmentation et expérience utilisateur. Les niveaux possibles sont les suivants :
- 0_MINIMAL
- 1_INTERMEDIATE
- 2_REINFORCED
- 3_HIGH
- HARDENING_ACTION : Le nom de l’action de durcissement précédé d’un identifiant non-nécessairement unique. Dans le cas des Recommandations de sécurité relatives à un système GNU/Linux, l’identifiant est constitué d’un R suivi d’un nombre, par exemple R30. Le but étant de garder la même nomenclature pour un même référentiel.
Lorsque vos dossiers sont créés, il ne manque plus deux fichiers playbook.yml.j2 et questions.yml. Le contenu de ces fichiers sera décrit dans les parties playbook.yml.j2 et questions.yml.
Sous-sections de AutomA Playbooks
Tester les playbooks
Les playbooks une fois créés doivent être testé pour vérifier la bonne conformité de l’action de durcissmenent. Pour simplifier le processus, nous mettons à disposition des containers Dokcer permettant alors de tester les playbooks.
Chaque environment doit avoir son propre container à la bonne version. Par exemple même si Debian 11 et Debian 12 sont proches en terme de fonctionnement, il en reste néanmoins nécesseraire de séparer les deux versions en deux images dockers différentes.
Remarque
Il est probable que certaines actions de durcissement ne peuvent pas être testées sur un environnement containeurisé. Il sera nécessaire alors d’effectuer les tests sur une machine virtuelle.
Images Docker existante
Vous trouverez les images dockers ici. Il sera uniquement nécessaire d’effectuer un pull.
Images Docker manquante
Faire une requête
Vous pouvez nous envoyer une demande par mail ou ouvrir une issue ou une discussion sur le Github d’AutomA.
Créer l’image
Dans cette partie, nous traiterons l’exemple pour une image de Debian 12, cependant le processus restera identique quel que soit l’environment que vous contenairiser.
Prérequis
La liste ci-après décrit l’ensemble des composants nécessaires pour la création d’une image :
- python3
- python3-pip
- python3-venv
- sshpass
ensuite effectuer les commandes :
python3 -m venv .venv
source .venv/bin/activate
python3 -m pip install ansible-core
Dockerfile
Dans un fichier nommé Dockerfile :
FROM debian:12
RUN apt-get update -y && \
apt-get install openssh-server sudo python3 -y
RUN sed -i "s/#PermitRootLogin prohibit-password/PermitRootLogin Yes/" /etc/ssh/sshd_config
RUN useradd -m -s /bin/bash user && \
echo 'user:password!' | chpasswd && \
echo 'root:password!' | chpasswd && \
service ssh restart
EXPOSE 22
CMD ["/usr/sbin/sshd", "-D"]
Pour créer votre image : docker build -t automa-debian12 . (N’oubliez pas le point à la fin de la commande !)
Dès que la commande est terminée, vous pouvez instancier votre image en container :
docker run -d -p 2222:22 --name debian-ssh-container automa-debian12
Fichiers nécessaires
inventory.yml
Ce fichier donne la configuration de notre container à Ansible.
all:
hosts:
docker-debian12:
ansible_host: 127.0.0.1
ansible_port: 2222
ansible_user: user
ansible_password: password!
ansible_become: yes
ansible_become_method: sudo
ansible_become_user: root
ansible_become_password: password!
playbook.yml
Le fichier playbook est celui qui sera donnée à Ansible pour qu’il puisse appliquer une règle sur le container. En voici un exemple :
---
- name: "Disable unused user accounts"
hosts: "all"
tasks:
- name: "List all users"
ansible.builtin.getent:
database: "passwd"
split: ":"
register: "all_users"
- name: "Disable user"
ansible.builtin.user:
name: "{{ item }}"
state: "absent"
with_items: "{{ all_users.ansible_facts.getent_passwd }}"
when:
- item not in ['root','user','_apt','sshd']
Tester !
Vous pouvez lancer la commande suivante :
python3 -m ansible playbook -i inventory.yml -l all playbook_example.yml -vvv
Fichier playbook.yml.j2
Les playbooks sont des modèles Jinja de playbooks Ansible. Cela nous permet de rendre les playbooks en fonction des paramètres définis par l’utilisateur.
Exemple
---
- name: "R30_Disable_User"
hosts: "all"
tasks:
- name: "Disable user"
ansible.builtin.user:
name: {% raw %}"{{ item }}"{% endraw %}
state: "absent"
with_items: "{{ used_users }}"
Cette règle mélange le rendu AutomA jinja et le rendu Ansible jinja. La variable used_users est celle fournie par le questions.yml, elle sera donc codée en dur dans le playbook. Pour la variable item, elle est entourée de balises jinja raw pour forcer l’absence de rendu de cette variable par le moteur de rendu AutomA car c’est une variable rendue par Ansible.
Fichier questions.yml
Cette page contient les spécifications des types de variable utilisés dans les template jinja de playbook.
Exemple
---
id: "The ID of the rule"
title: "The title of the Rule"
description: "The description of the rule"
author: "The author name"
last_modified: "MM/DD/YYYY of the corresponding last modifiction"
tags:
- "Tag1"
- "Tag2"
questions:
- title: "The first value to fill"
name: "The name of the variable to render with this result"
required: "A boolean to say if the value can be None or not"
type: "One of the defined types"
value: "None by default, the value filled by this question"
- title: "The first value to fill"
name: "The name of the variable to render with this result"
required: "A boolean to say if the value can be None or not"
type: "One of the defined types"
value: "None by default, the value filled by this question"
### EXAMPLE ###
---
id: "R42"
title: "This rule is an example"
description: "You will answer a famous question: what is the life answer ?"
author: "aiglematth"
last_modified: "10/24/2023"
tags:
- "life"
- "answer"
questions:
- title: "What is the answer of the life ?"
name: "life_answer"
required: yes
type: "u8"
value:
- title: "Are you sure of your answer ?"
name: "are_you_sure"
required: yes
type: "bool"
value:
Types
| Type | Description |
|---|
str | Simple chaine de caractères |
list<x> | Liste de type x |
choice<x>[y1,y2,...] | Liste de choix y1, y2, … de type x |
Contribuer
Objectif
Ce document a pour objectif de proposer une procédure à suivre pour développer sur le projet AutomA. Cette procédure s’applique que vous soyez interne ou externe au projet.
Procédure
A - ISSUE
Quelque soit le dépôt github sur lequel vous voulez travailler, vous devez créer une issue en y mettant les éléments nécessaires. L’issue doit impérativement être rédigée en anglais.
Prenons le cas suivant : vous voulez effectuer une nouvelle recommandation de l’ANSSI par exemple la recommandation R30, voici les champs à remplir :
| Champ | Contenu |
|---|
| Titre | [Make-Rule] R30 - Disable unused user accounts |
| Commentaire | Todo : questions.yml + playbook.yml From : ANSSI Rule : 30 Level : Minimal |
De plus si vous êtes dans le projet, vous devez rajouter :
| Champ | Contenu |
|---|
| Assignés | la ou les personnes qui travaillent dessus |
| Labels | [TODO]+[enhancement] |
| Projet | Kanban (penser à mettre en TODO sur le projet dès que créée) |
B - BRANCHE
Cas : Vous travaillez sur le dépôt source du projet
Depuis la page de l’issue, vous pouvez créer une branche de développement associée à celle-ci. Un simple clic sur “Créer une branche” permet de faire afficher une pop-up qui demande plusieurs informations. Vous n’avez pas besoin de changer les informations par défaut.
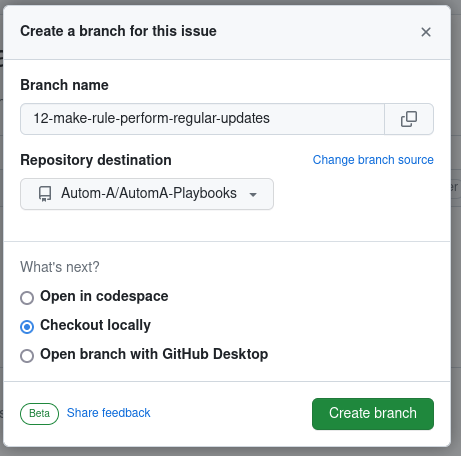
Vous avez maintenant une branche pour développer ! N’oubliez pas de changer de branche (sur vscode un clic en bas à gauche). Voici les commandes à faire dans votre terminal :
# Pour récupérer les modifications du dépôt, notamment la nouvelle branche
git fetch --all
# Changer de branche de développement
git checkout <nom_de_votre_branche>
# Vérifier
git branch --show-current
Cas : Vous travaillez sur un fork du projet
Vous devez forker le projet sur votre compte, cela vous permettra d’obtenir les droits pour modifier le code. Une fois sur votre dépôt, vous pouvez soit directement développer sur votre branche main ou créer des branches auxiliaires comme nous faisons sur le dépôt officiel.
C - FUSION
Se mettre à jour
Cas : Vous travaillez sur le dépôt source du projet
Avant de demander à pousser vos modifications sur la branche principale, vous devez vous assurez que vous n’écraserez pas le travail des autres contributeurs. Pour se faire, vous devez dans un premier temps mettre à jour votre branche au même niveau que la branche main.
Depuis votre branche de développement, effectuer les commandes suivante (dans l’ordre):
git checkout <votre_branche_de_developpement>
git fetch
git merge origin/main
# Gestion de conflits sur votre branche
# (en ligne de commande ou via votre IDE)
git push
Cas : Vous travaillez sur un fork du projet
Vous devez ajouter le dépôt officiel en remote supplémentaire.
git remote add source <url_depot>
Mettre à jour votre branche :
git pull source <votre_branche_de_developpement>
Vous devez gérer les conflits qui peuvent subvenir tout en veillant à ne pas casser le code déjà existant. Votre dépôt local est maintenant à jour, il faut mettre à jour votre dépôt distant :
Effectuer la demande de fusion
Depuis l’interface web de github, vous pouvez effectuer une “pull-request” pour fusionner votre branche à la branche main. Lorsque le nombre de relecteurs correspond au nombre minimun, vous pourrez valider la fusion.